
cross-posted from: https://lemmy.world/post/1709025
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
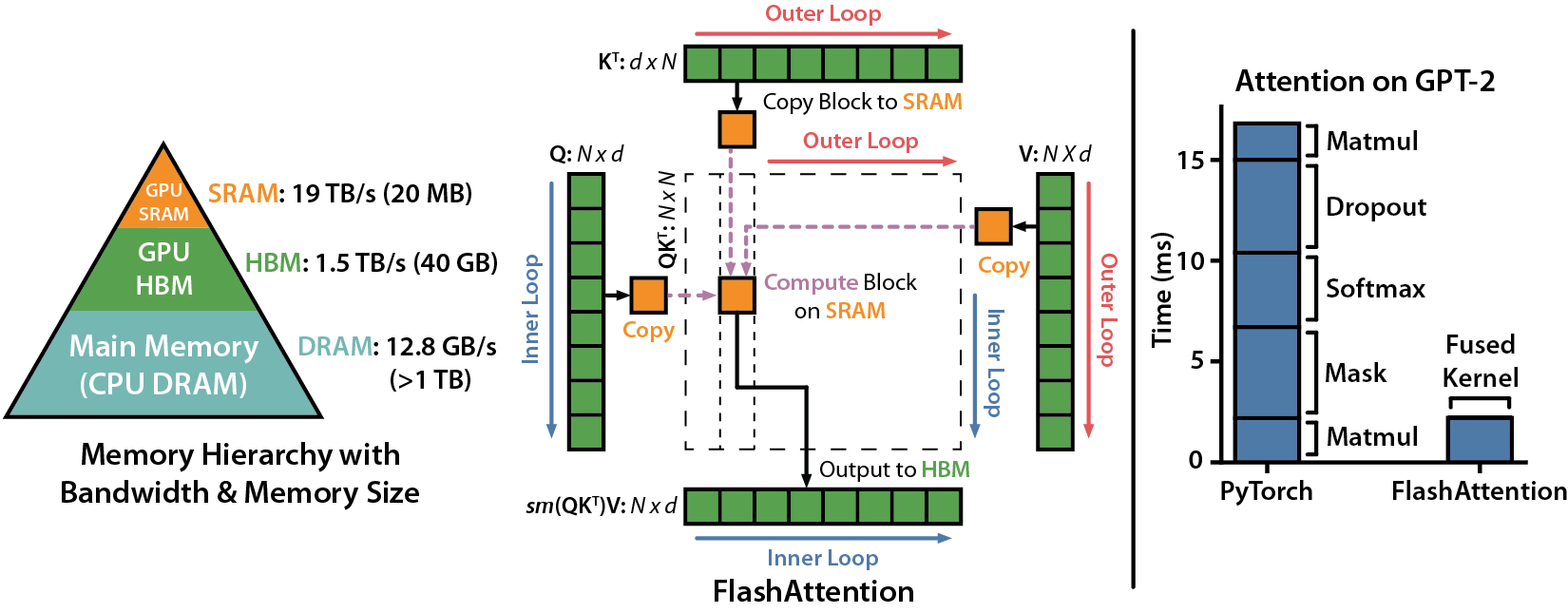
Today, we explore an exciting new development: FlashAttention-2, a breakthrough in Transformer model scaling and performance. The attention layer, a key part of Transformer model architecture, has been a bottleneck in scaling to longer sequences due to its runtime and memory requirements. FlashAttention-2 tackles this issue by improving work partitioning and parallelism, leading to significant speedups and improved efficiency for many AI/LLMs.
The significance of this development is huge. Transformers are fundamental to many current machine learning models, used in a wide array of applications from language modeling to image understanding and audio, video, and code generation. By making attention algorithms IO-aware and improving work partitioning, FlashAttention-2 gets closer to the efficiency of General Matrix to Matrix Multiplication (GEMM) operations, which are highly optimized for modern GPUs. This enables the training of larger and more complex models, pushing the boundaries of what’s possible with machine learning both at home and in the lab.
Features & Advancements
FlashAttention-2 improves upon its predecessor by tweaking the algorithm to reduce the number of non-matrix multiplication FLOPs, parallelizing the attention computation, and distributing work within each thread block. These improvements lead to approximately 2x speedup compared to FlashAttention, reaching up to 73% of the theoretical maximum FLOPs/s.
Relevant resources:
Installation & Requirements
To install FlashAttention-2, you’ll need CUDA 11.4 and PyTorch 1.12 or above. The installation process is straightforward and can be done through pip or by compiling from source. Detailed instructions are provided on the Github page.
Relevant resources:
Supported Hardware & Datatypes
FlashAttention-2 currently supports Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon. It supports datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs). All head dimensions up to 256 are supported.
Relevant resources:
The/CUT
FlashAttention-2 is a significant leap forward in Transformer model scaling. By improving the efficiency of the attention layer, it allows for faster and more efficient training of larger models. This opens up new possibilities in machine learning applications, especially in systems or projects that need all the performance they can get.
Take Three: Three big takeaways from this post:
Performance Boost: FlashAttention-2 is a significant improvement in Transformer architecture and provides a massive performance boost to AI/LLM models who utilize it. It manages to achieve a 2x speedup compared to its predecessor, FlashAttention. This allows for faster training of larger and more complex models, which can lead to breakthroughs in various machine learning applications at home (and in the lab).
Efficiency and Scalability: FlashAttention-2 improves the efficiency of attention computation in Transformers by optimizing work partitioning and parallelism. This allows the model to scale to longer sequence lengths, increasing its applicability in tasks that require understanding of larger context, such as language modeling, high-resolution image understanding, and code, audio, and video generation.
Better Utilization of Hardware Resources: FlashAttention-2 is designed to be IO-aware, taking into account the reads and writes between different levels of GPU memory. This leads to better utilization of hardware resources, getting closer to the efficiency of optimized matrix-multiply (GEMM) operations. It currently supports Ampere, Ada, or Hopper GPUs and is planning to extend support for Turing GPUs soon. This ensures that a wider range of machine learning practitioners and researchers can take advantage of this breakthrough.
Links
If you found anything about this post interesting - consider subscribing to !fosai@lemmy.world where I do my best to keep you informed in free open-source artificial intelligence.
Thank you for reading!
Errr could someone ELI just a regular person?
Here’s a transformer (GPT-4) describing this advancement in transformer architecture:
Sure, let’s break this down like you’re five years old!
Imagine you’re playing with a big set of Lego blocks (think of these as your data). You have a big task: you need to sort all of these blocks based on their colors, size, and shapes (this is similar to processing information in a machine learning model).
At first, you try to do it all by yourself (this is like the original Transformer model). It takes a long time, and your hands get really tired (this means the model takes a lot of time and computer memory).
Then, your older brother comes in with a new plan. He tells you, “Hey, why don’t we divide the work?” He helps you sort the blocks by colors, and you sort them by size and shapes (this is like the ‘work partitioning’ in FlashAttention-2).
Also, your older brother suggests, “Let’s do it together instead of one after another”. So, while he’s sorting by color, you’re sorting by size and shape at the same time (this is the ‘parallelism’ in FlashAttention-2).
This makes the job get done faster and you both don’t get as tired (meaning FlashAttention-2 is faster and uses less memory).
The new way of sorting is also super smart because it knows how to best use your toy boxes to keep your sorted Lego blocks (the ‘IO-aware’ part, with the toy boxes being the different levels of memory in the computer).
FlashAttention-2 is like your older brother’s plan, but for computer models. It helps them process big amounts of data more quickly and efficiently. This is great because it allows us to create even bigger and more exciting models that can understand things like language, pictures, and even generate music and videos.
And just like you needed to have enough space and the right kind of Lego blocks to play this sorting game, to use FlashAttention-2, you need some specific computer parts (like certain types of GPUs), and programming stuff (like CUDA and PyTorch).
This is a big deal because it makes our computer models better and faster. They can learn more and do more cool things, just like how you and your brother can sort more Lego blocks and have more fun with your new sorting plan!
@BitSound @angelsomething skynet is here!!
